The problem:
The logger-link problem in a nutshell is this: get the full list of links for #trilema loglines from my old logger (there’s the full dump on my site) and then make a script (possibly some curl involved as well) to find on trilema.com the corresponding correct link for each. Match them and produce a full record, similar to the one I published for #o. And sure, read, poke at it and ask as needed for clarification.
The trilema.com logs are here, and I believe the trilema logline dump from ossasepia is this link from the Raw Logs and Archives page.
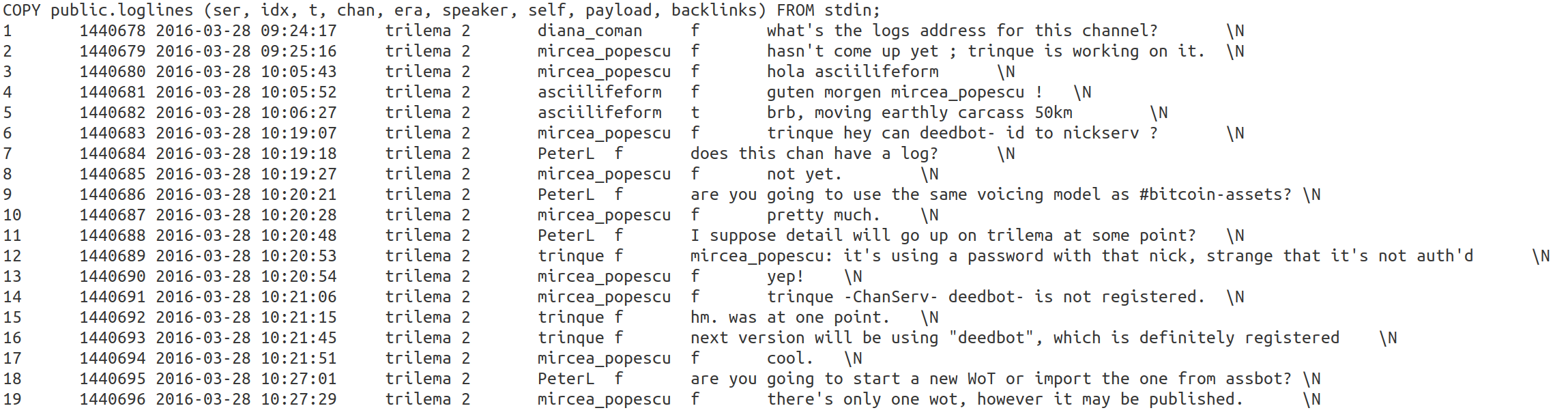
Below are the first lines from the raw logline dump:
And its corresponding trilema.com html version.
So, I think the task is to match each of those timestamped comments with its corresponding html link on trilema.com, eg. in the case of the first line:
1 1440678 2016-03-28 09:24:17 trilema 2 diana_coman f what’s the logs address for this channel? \N
needs to be matched with its corresponding Trilema.com log line:
|
diana_coman:
|
what’s the logs address for this channel?
|
[09:24]
|
I believe the similar record for #o logs Diana is referring to above is this one; found here; with the first line’s mapping as follows:
logs.ossasepia.com/log/ossasepia/2019-07-14#998683 ossasepia.com/2020/04/19/ossasepia-logs-for-14-Jul-2019#998683
If indeed that’s the task at hand, it seems that the index difference between the first comment from each source is 618545:
trilema.com first index: 2067223
raw logdump first index: 1448678
If that delta is constant, perhaps an awk script could be made to run through the raw logline dump, grab the date, time, author, index (adding the 618545 delta); format and output the corresponding trilema html links?